Recent Posts
GPU EATERのJupyter NotebookにWindowsクライアントからアクセスする
Introduction GPU EATERを利用されるユーザーの中には、Windows端末を利用される方もいらっしゃるかと思います。 そこで今回は「GPU EATERインスタンス内で起動したJupyter NotebookにWindowsクライアント上のブラウザからアクセスする」 方法について説明していきたいと思います。
本項で説明すること・しないこと 本項では次の内容について説明を行います。
Windows用仮想ターミナル(TeraTermを利用)でのポートフォワーディングを有効としたGPU EATERインスタンスへの接続 Windows端末上ブラウザでGPU EATERインスタンス内のJupyter Notebookにアクセスする為の各種設定 ただし、以下の内容
公開鍵・秘密鍵の作成方法 TeraTermの基本設定・マクロ構文 TeraTerm以外のWindows用仮想ターミナルソフト については説明を省略させていただきます。
Windows用仮想ターミナルの設定 はじめに、Windows用仮想ターミナルを利用してGPU EATERに接続する際、通常ではGPU EATERインスタンスのローカルホスト:8080番ポートで行われるJupyter Notebookの通信をWindows端末側のローカルホスト:8080番ポートに展開する「ポートフォワーディング」を行う方法について説明していきます。
TeraTerm用マクロの設定 TeraTermには複数のパラメータを利用するためのマクロが存在しております。今回はそれを利用してTeraTermでポートフォワード接続を確立します。
まずテキストエディタ(例・メモ帳)を開いて以下の内容を入力します。なお、カッコ内はそれぞれ「GPU EATERインスタンスのIPアドレス」 「接続に利用するSSH秘密鍵のパス」と書き換えてください。
username = 'root' hostname = '(ip4 address)' keyfile = '(/path/to/private_key)' msg = hostname strconcat msg ':22 /ssh /auth=publickey /user=' strconcat msg username strconcat msg ' /keyfile=' strconcat msg keyfile strconcat msg ' /ssh-L8888:localhost:8888' connect msg 作成したテキストファイルを’gpueater.
read more
エンジニアとしての成長に必要なものとは
Introduction GPUEATERの根岸です。 今回は若干趣向を変えて、以前社内での雑談中に中塚CTOが提示した「エンジニアとしての成長モデル」の紹介と、そのモデルを踏まえたシミュレーションの結果、そして シミュレーションの結果を踏まえたエンジニアとしての成長戦略についてお話ししていきたいと思います。
中塚の考える「エンジニアに必要なもの」 略歴は別紙に譲りますが、当社CTO中塚はエンジニアとしては非常に数奇な経験を経て現在のキャリアに至っております。 その中塚が言うには「エンジニアとして成長するには次の二つが極めて大事なのでは無いか」とのこと。
十分な休息(睡眠時間) コーディングの経験 ソフトウェアエンジニアとしては業務としてコードを書く時間は一定数あるかと思いますが、ただ業務で書くのみに及ばず終業後や休日にもコードに触れる貪欲さが無いと 頭ひとつ抜けたエンジニアにはなれない、と中塚は語ります。 同時に、エンジニアとして大きな成長を得るためには十分な睡眠が不可欠、とも語っておりました。
エンジニアの成長モデル また、同時に中塚は次の様なコードで、エンジニアの成長モデルを模式化しておりました。
%matplotlib inline import matplotlib.pyplot as plt import numpy as np import math # エンジニアの成長曲線計算機 # ------------------------------------- LEVEL = 3 # 現在のレベル G=0.5 # センス・才能 W_CODING_TIME = 5 # 平日での平均コーディング時間 O_CODING_TIME = 2 # 平日夜に勉強または趣味でやってる平均コーディング時間 H_CODING_TIME = 0 # 休日に勉強または趣味でやってる平均コーディング時間 SLEEPING_TIME = 8 # 平均睡眠時間 year = 2.0 # 1.0 = 365日 # ------------------------------------- # 1~10:日本の初級者の平均 # 10~20:日本の中級者の平均 # 20~30:日本の上級者の平均 # 30~40:USの上級者の平均 # 50~:スタークラス def sg(x): return 1/(1+math.
read more

第一回CDLEハッカソン GPU EATER賞受賞者に聞く。GPU EATERの活用方法。
Introduction 今回はGPU EATERがスポンサーとして株式会社A.L.I. Technologiesと共同で計算リソースを提供させていただいた、一般社団法人 日本ディープラーニング協会主催『CDLEハッカソン』のGPU EATER賞を受賞したチームのお二人に、GPU EATERの使い心地、AMD社製RADEON VII GPUを使った感想などをうかがいました。 GPU EATER賞を受賞されたニューラルポケットチームの馬目さんと星山さん 馬目さん(右):ブレインズコンサルティング株式会社のチーフエンジニア。2013年、エンジニアのキャリアをスタートし、その後、データ分析/機械学習/深層学習を独学で習得する。ゲーム業界の仕事に興味を持っていたことからセンサと機械学習の組み合わせを研究していたところ、ある大手日系自動車メーカーの先行開発に携わることになる。現在は人工知能を用いた業務改善のコンサルティングを提供する企業で、クライアントの課題に応じたPoCアプリをインフラからアプリ、モデルまでをフルスタックに開発している。
星山さん(左):大学・大学院で金属材料を研究。現在は、日系自動車系メーカー勤務。本業の傍、子供の頃から好きだったというプログラミングを再開、アプリの趣味開発などを10年以上に渡って続けている。3年前に「人工知能は私たちを滅ぼすのか」という書籍に出会い、描かれていた未来に強く感銘を受けたことをきっかけに、データ分析/機械学習/深層学習を独学で習得。最近は、人工知能搭載アプリをディープラーニングを使って構築中。
ー GPU ETAER賞の受賞おめでとうございます!今回ハッカソンに参加されたきっかけを教えてください。
馬目さん(以下:馬):私はハッカソンへ参加することが趣味なので、今回も自然な流れで参加を決めました。ディープライニング検定G資格は去年取得しました。会社が受験料を負担してくれるということだったので(笑)
星山さん(以下:星):私は独学で進めていましたが、独学の限界と言いますか、ディープラーニングの実用的な活用方法や深い部分がいまいちピンときていなかったので、ハッカソンに参加したらもっと色々わかるのではないかと思い参加ました。あとは、先端でやっている方々の技術レベルを知りたかったというのもあります。参加してみたら知見や経験が豊富な方もいて刺激になりました。また、自分の得意な技術と不得意な技術があるということもよくわかりました。
ー皆さんのアウトプットのクオリティには驚きました。短期間でモデル構築からデモアプリ作成まで、さぞハードだったのではないかと想像します…。今回のハッカソンにはどれくらいの時間を使われましたか?
星:私が費やした時間はおよそ50~60時間くらいだと思います。ディープラーニングの実装にかけられた時間はその半分以下です。
馬:私たちのチームはWEBアプリをフロントのできる人と星山さんにお願いして、ディープラーニングを他の2人にお願いし、私は対話アプリをバックエンド、フロントエンドの両方を担当しました。WEBアプリ側が落ち着いてきてからは、星山さんにもディープラーニングの部分をお願いしました。ハッカソンには48時間ほど費やしましたが、発表の前日時点で動くものが何もない状態でしたから、JDLAの事務所へ泊まり込み、徹夜でしあげました(笑)。
ーそれは本当にお疲れ様でした…!最後の一週間がみなさん大変だったと聞いています。時間のない中で効率よく進めるのは大変だったと思いますが、その中でGPU EATERはどのように活用されたのでしょうか?
馬:データの前処理、ディープラーニングの学習からWebのバックエンド/フロンドエンドと今回は全面的に活用しました。最初に試してたのは今回GPU EATERと共にリソース提供されていたAbejaプラットフォームですが、Abejaプラットフォームはマニュアルを読まなくては利用できないかなというところで、学習コストを払わなくてはならない問題がありました。
星:限られた時間を有効に使うというところで、GPU EATERは使い慣れている環境なので学習コストを払うことなくすぐに開始することができます。やはりLinux環境がそのまま提供されているので自由度も高くとても使いやすかったです。
馬:何かうまくいかないことがあってもすぐに解決することができますからね。今回は、提供されたデータのサイズが大きかったので、GPU EATERがなかったら相当困ったと思います。また、GPUのVideo RAMサイズも16GBと大きなものが搭載されていたのも助かりました。
星:今回のハッカソンに限らず、家のパソコンでディープラーニング学習環境を構築する場合はTensorflowのバージョンに合わせたCUDAのバージョンやドライバのバージョンを揃える必要があり、バージョンアップの度に大幅な時間を取られていました。GPU EATERの場合、すぐに使えるというのが私にとっては一番のメリットだと気づきました。
ー途中でつまずくようなことはなかったですか?
馬:うーん、強いてあげるなら通信ポートの開け閉めの方法がわからないとか、dockerのコンテナを実行した際にエラーが出たとかいくつかの問題はありましたが、使い慣れているLinux環境なのでそうしたレベルの問題ならいくらでも解決する手段があります。そういう意味で大きく困ったということはありませんでしたね。
ーわかりにくい場所にありますが、ポートの開閉はGPU EATERのダッシュボードからできますので、次回はぜひ活用してみてください。
ーAMD社製 RADEON VII GPUを使用していたことについてはいかがですか?使う前との印象の違いなどはありますか?
馬:以前、ROCmベースでTensorflowをビルドしようとしたことがありますが、当時はかなり大変でした。その時と比較するとだいぶ変わった印象があります。
星:機械学習でAMD GPUを利用するのは初めてでしたがTensorFlowさえちゃんと動いてくれたら、GPUやミドルウェアのことは気にする必要がありません。
馬:インスタンスを使ってみてAMD GPUはNVIDIA GPUと遜色ない事が分かったので、どんどん広めていって欲しいと思います。価格的にも安いですしね。
ーありがとうございます。今回利用したディープラーニングのモデルについても教えてください。
星:今回はTensorFlowで隠れ層が一層くらいの
シンプルなLSTMでモデルを作りました。時間があれば本当はもっと色々試したいことがありました。モデル周りはもう少しやりようがあったかなぁと思っています。
ー今回のハッカソンでは実現できたことや更に挑戦したいことなどあったのではないかと思います。今後のディープラーニングとの関わり方は、どのように考えてらっしゃいますか?
馬:今まで通り、趣味でも仕事でも関わっていきたいと思っています。ディープラーニングもクライアントの要望を叶えるためのツールのひとつですので、基礎研究というよりかは応用分野で付き合っていくつもりです。上手い活用方法を常に探ってお客さまにとって良いものを生み出していきたいです。
星:自社の工場では今も目視で品質検査が行われるところがたくさんありますから、ディープラーニングを使ってそう言った作業の自動化にも積極的にチャレンジしていきたいなと考えています。プライベートでは人の役に立つものを作りたいと考えています。自宅にムカデがよく出るので試しに「ムカデ認識」のモデルを作っていますが、ムカデに限らず害虫や家畜などの領域でも活用できるのではないかと思っています。
ーお忙しいところをどうもありがとうございます。今回 GPUEATER賞ということでハッカソンに利用したインスタンスを3ヶ月分自由にお使いいただけます。どのような事に使いたいですか?
星:丁度家の学習環境が壊れているのでとても助かります。認識モデルの学習や今後はKaggleにも挑戦できたらと考えています。
ー頂戴した点は早速改善して行きたいと思います。本日はお忙しい中、どうもありがとうございました。 ※GPU EATER賞:8/31(土)〜9/28 (土) に開催されたJDLA主催のCDLEハッカソンの副賞(GPUインスタンス 無料券 3ヶ月分)。CDLEハッカソン開催期間中に、同ハッカソン用GPU EATERインスタンスを用いて、最もDeep Learningの学習を行ってくださったチームを選考させていただきました。
パートナー企業募集中 現在Pegaraでは、企業や研究機関向けの特別プランをご提案させていただいております。
ご興味ある方はお気軽にご連絡ください。
お問い合わせ先はこちら:info@pegara.com
read more
ROCmとNVIDIAベンチマークの比較(推論)
Introduction 2019年10月現在、ROCmのバージョンは2.8を数えるまでになりました。 ROCm環境での機械学習モデルの動作は、推論・学習ともにバージョンが上がるにつれて改善してきています。この記事ではTensorflow1.14での推論を対象として、ROCmが同時期に提供されているCuda環境下で動作させたNVIDIA GeForce RTX 2080tiと比較してどの程度の実行効率を誇るかを比較していきます。 検証環境 検証を行ったAMD Radeon環境およびNVIDIA GeforceRTXの環境を以下に記します。
まずは、AMD Radeon環境については以下の通りとなります。
OS:Ubuntu16.04 GPU:AMD RadeonVII or AMD RX Vega 64 ROCm:2.6 Software:Tensorflow 1.14 続いて、NVIDIA GeForce環境となります。
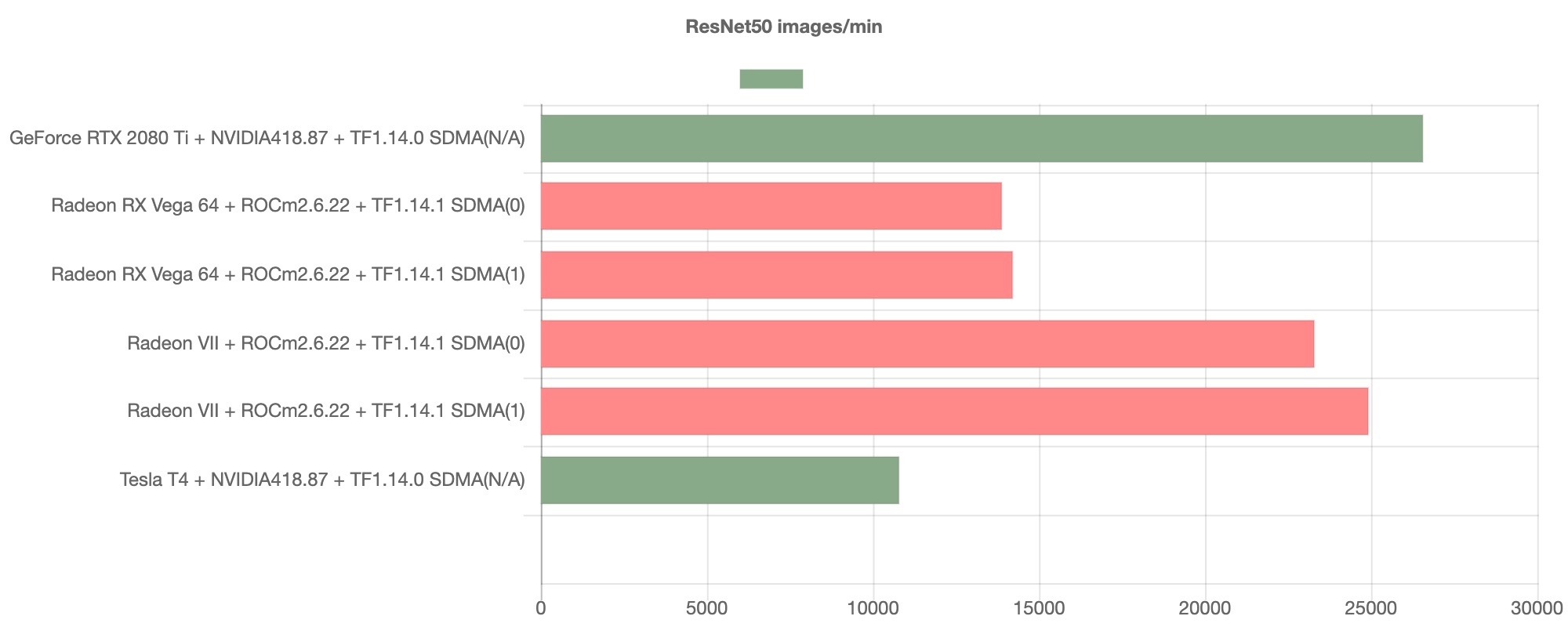
OS:Ubuntu16.04 GPU:NVIDIA Geforce RTX2080ti Cuda:10.0 Software:Tensorflow 1.14 検証結果 ResNet50 ResNet50におけるベンチマーク結果は以下の通りとなります。
グラフが示すように、AMD GPUのスループットは著しく向上しており、NVIDIA GPUの代替として通用しうる速度を発揮することが見て取れます。
MobileNet 続いてMobileNetのベンチマーク結果を以下に示します。
こちらも推論タスクのスループットは良好であり、NVIDIA GPUと比較して競合となりうる高い性能を発揮していることが伺えます。
YOLOv3 ここまで、ROCm環境のAMD GPUが極めて良好なスループットを示したモデルを紹介してきましたが、続いて見ていくYOLOv3のベンチマークはどうなるでしょうか。
このグラフからは、ROCm環境上のAMD GPUでは一転してNVIDIA GPUに対して苦戦していることが見て取れます。
Inception-V3 続いて、Inception-V3のベンチマークを見ていきたいと思います。
こちらでも、YOLOv3ほど顕著ではないものの、AMD GPUのスループットはNVIDIA GPUのものと比較して苦戦しているものということが見て取れます。
考察 以上、現在のROCm環境下でのAMD GPUの推論タスクのベンチマークおよびNVIDIA GPUでのものと比較していきましたが、現在のところResNetやMobileNetの様にAMD GPUで良好なスループットを確保できるモデルがある一方で、YOLOv3やInception-V3の様にスループットの面でNVIDIA GPUに譲るモデルが存在していることが見て取れます。 このことから、推論に用いる機械学習モデルによってはAMD GPUを選択する余地があるということを確認する一方で、現在処理のスループットにおいてNVIDIA GPU環境に劣るモデルのボトルネックとなっている箇所についてより深く調べていく必要があるかと思われます。
References TensorFlor-ROCm / HipCaffe / PyTorch-ROCm / Caffe2 installation https://rocm-documentation.
read more

AMD RadeonGPU上でCenterNet
Introduction M2Detよりもより良いObjectDetectionの論文が出ていたのでRadeonGPU上で動作確認を行いました。M2Detも中国勢でCenterNetも中国系の人が書いたCenterNetというモデルです。論文の通りであればYoloV3< M2Det< CenterNetとなる最も精度が高く軽いモデルになります。 CenterNet: Keypoint Triplets for Object Detection https://arxiv.org/abs/1904.08189
PyTorch実装 https://github.com/xingyizhou/CenterNet/blob/master/readme/INSTALL.md
Keras実装 https://github.com/see--/keras-centernet
動作確認 クローンして必要なパッケージを入れます。
git clone https://github.com/see--/keras-centernet cd keras-centernet sudo pip3 install -r requirements.txt
必要パッケージは
Keras==2.2.4 opencv-python==3.4.3.18 tqdm==4.26.0 youtube-dl==2019.4.30 pytest==4.4.1 Pillow==6.0.0 matplotlib==3.0.3 Cython==0.29.7 pycocotools==2.0.0 KerasのBackendはtensorflow-rocm 1.13.3を使用します。 youtube-dlは今回は不要です。
以下のコマンドでROCm-TensorFlow上でGPU(RadeonVII)を確認。
python3 -c "from tensorflow.python.client import device_lib; device_lib.list_local_devices()" johndoe@thiguhag:~$ python3 -c "from tensorflow.python.client import device_lib; device_lib.list_local_devices()" 2019-04-15 23:10:40.484698: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.
read more