POSTS
ROCmとNVIDIAベンチマークの比較(推論)
Introduction
2019年10月現在、ROCmのバージョンは2.8を数えるまでになりました。
ROCm環境での機械学習モデルの動作は、推論・学習ともにバージョンが上がるにつれて改善してきています。この記事ではTensorflow1.14での推論を対象として、ROCmが同時期に提供されているCuda環境下で動作させたNVIDIA GeForce RTX 2080tiと比較してどの程度の実行効率を誇るかを比較していきます。
検証環境
検証を行ったAMD Radeon環境およびNVIDIA GeforceRTXの環境を以下に記します。
まずは、AMD Radeon環境については以下の通りとなります。
OS:Ubuntu16.04
GPU:AMD RadeonVII or AMD RX Vega 64
ROCm:2.6
Software:Tensorflow 1.14
続いて、NVIDIA GeForce環境となります。
OS:Ubuntu16.04
GPU:NVIDIA Geforce RTX2080ti
Cuda:10.0
Software:Tensorflow 1.14
検証結果
ResNet50
ResNet50におけるベンチマーク結果は以下の通りとなります。
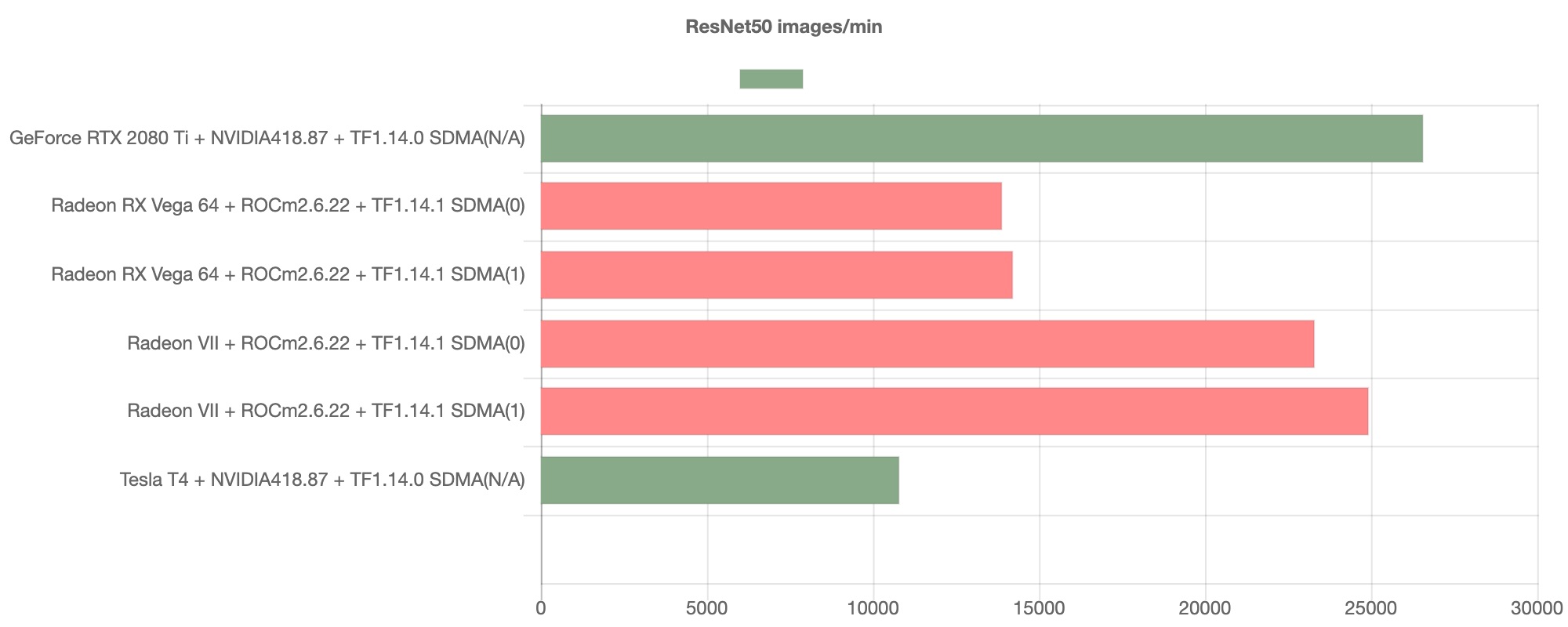 グラフが示すように、AMD GPUのスループットは著しく向上しており、NVIDIA GPUの代替として通用しうる速度を発揮することが見て取れます。
グラフが示すように、AMD GPUのスループットは著しく向上しており、NVIDIA GPUの代替として通用しうる速度を発揮することが見て取れます。
MobileNet
続いてMobileNetのベンチマーク結果を以下に示します。
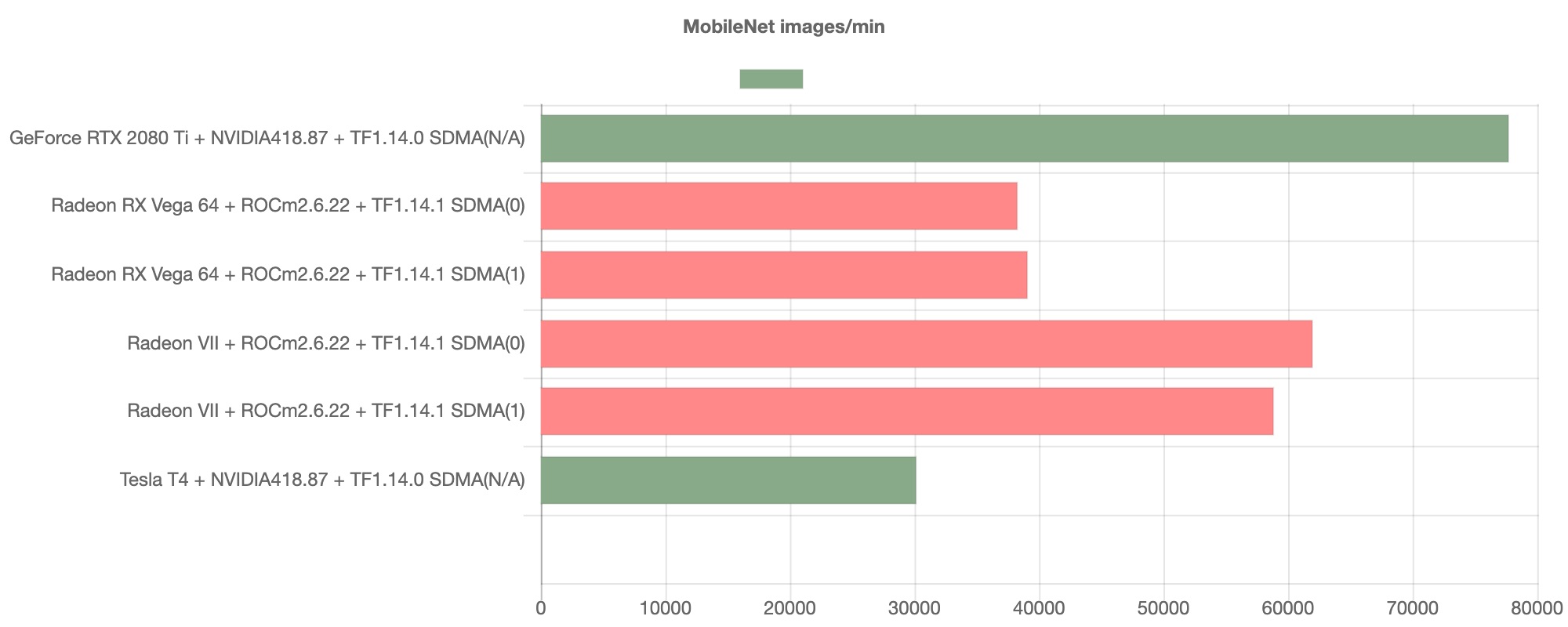 こちらも推論タスクのスループットは良好であり、NVIDIA GPUと比較して競合となりうる高い性能を発揮していることが伺えます。
こちらも推論タスクのスループットは良好であり、NVIDIA GPUと比較して競合となりうる高い性能を発揮していることが伺えます。
YOLOv3
ここまで、ROCm環境のAMD GPUが極めて良好なスループットを示したモデルを紹介してきましたが、続いて見ていくYOLOv3のベンチマークはどうなるでしょうか。
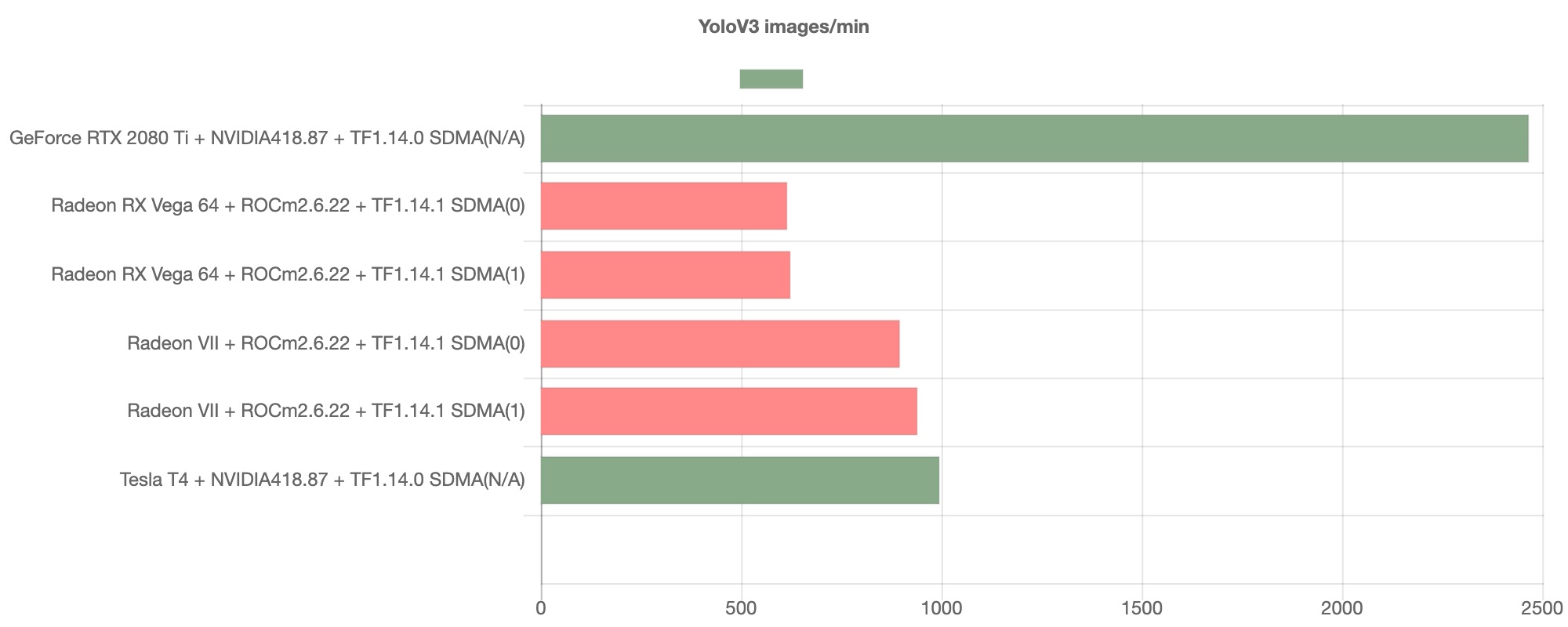 このグラフからは、ROCm環境上のAMD GPUでは一転してNVIDIA GPUに対して苦戦していることが見て取れます。
このグラフからは、ROCm環境上のAMD GPUでは一転してNVIDIA GPUに対して苦戦していることが見て取れます。
Inception-V3
続いて、Inception-V3のベンチマークを見ていきたいと思います。
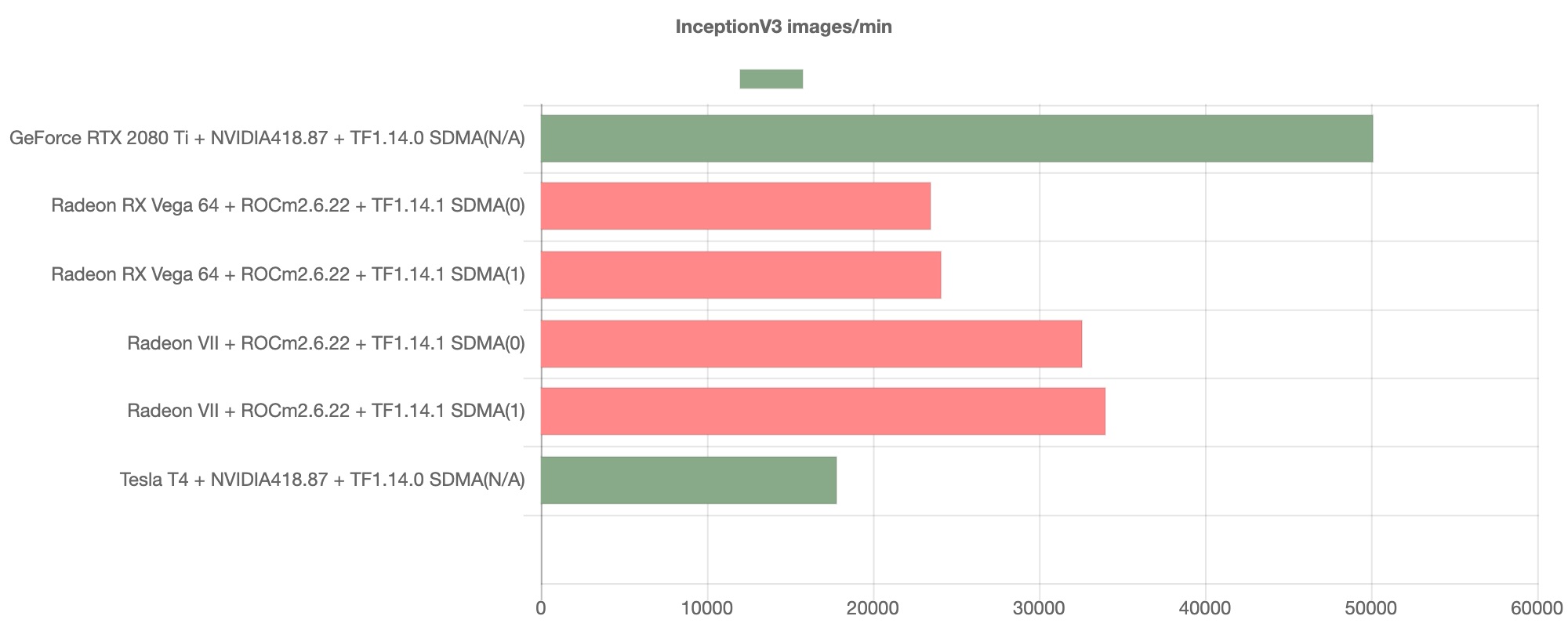 こちらでも、YOLOv3ほど顕著ではないものの、AMD GPUのスループットはNVIDIA GPUのものと比較して苦戦しているものということが見て取れます。
こちらでも、YOLOv3ほど顕著ではないものの、AMD GPUのスループットはNVIDIA GPUのものと比較して苦戦しているものということが見て取れます。
考察
以上、現在のROCm環境下でのAMD GPUの推論タスクのベンチマークおよびNVIDIA GPUでのものと比較していきましたが、現在のところResNetやMobileNetの様にAMD GPUで良好なスループットを確保できるモデルがある一方で、YOLOv3やInception-V3の様にスループットの面でNVIDIA GPUに譲るモデルが存在していることが見て取れます。 このことから、推論に用いる機械学習モデルによってはAMD GPUを選択する余地があるということを確認する一方で、現在処理のスループットにおいてNVIDIA GPU環境に劣るモデルのボトルネックとなっている箇所についてより深く調べていく必要があるかと思われます。
References
- TensorFlor-ROCm / HipCaffe / PyTorch-ROCm / Caffe2 installation https://rocm-documentation.readthedocs.io/en/latest/Deep_learning/Deep-learning.html
- ROCm https://github.com/ROCmSoftwarePlatform
- MIOpen https://gpuopen.com/compute-product/miopen/
- GPUEater tensorflow-rocm installer https://github.com/aieater/rocm_tensorflow_info
お知らせ
現在Pegaraでは、企業や研究機関向けのGPUEaterの利用を募集しております。 また、GPUEaterの開発普及を一緒に行うメンバーを募集しています。 募集職種はこちら