POSTS
ベンチマーク TensorFlow上でCIFAR10とAMD GPUs上でROCm 対 NVIDIA GPUs上でCUDA9とcuDNN7
Introduction
前回に続きCIFAR10のベンチマークを記述していきます。
前回までの記事
2018年3月7日 Benchmarks on MATRIX MULTIPLICATION | A comparison between AMD Vega and NVIDIA GeForce series 2018年3月20日 Benchmarks on MATRIX MULTIPLICATION | TitanV TensorCore (FP16=>FP32)
CIFAR10
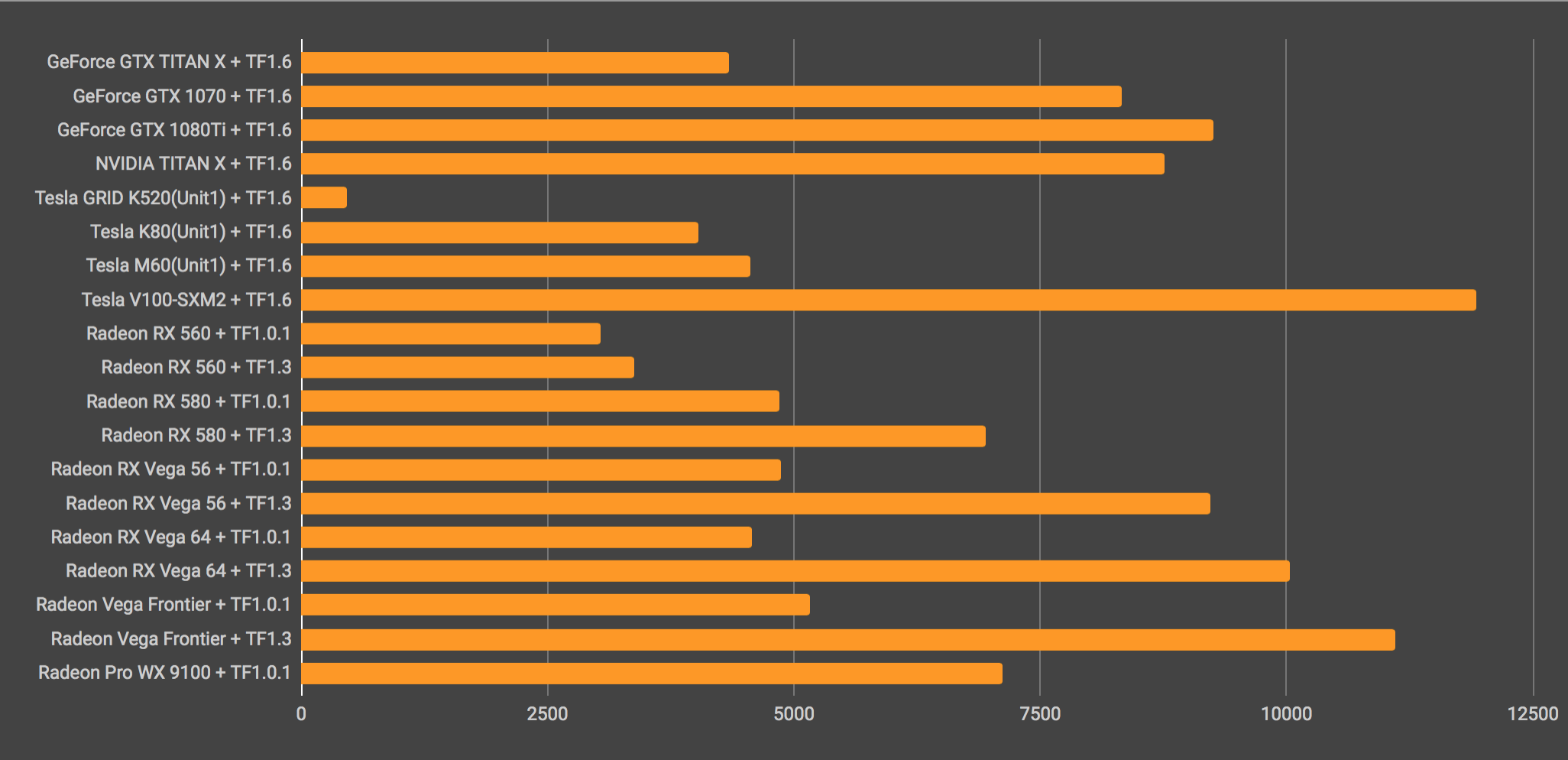 Average examples pre second
Average examples pre second
計算指標
゙世界コンペティションやベンチマークでよく使用される CIFAR10 を TensorFlow の公式を使用し 、学習スピードを計測するものとしました。今回の記事は、”CIFAR10”のみ掲載します。
ベンチマークに使うプログラムはこちらを使用しました。 https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10
動作環境
For AMD(TF1.0.1): Ubuntu 16.04.3 x64 HIP-TensorFlow 1.0.1 Python 2.7 Driver: ROCm 1.7
For AMD(TF1.3): Ubuntu 16.04.4 x64 TensorFlow 1.3 Python 3.5 Driver: ROCm 1.7.137
For NVIDIA: Ubuntu 16.04.4 x64 TensorFlow r1.6 Python 3.5 Driver: 390.30, CUDA9.0, cuDNN7
考察
前回取った行列演算のBenchmarkに近い結果が得られました。HIP-TensorFlow1.0.1を使った場合は奇怪な結果が取れており、1世代前のRX580がVega64に勝っているところから、明らかにAMD側の環境に問題がありましたが、新しいROCmと、TensorFlow1.3にバージョンが上がったところでスピードに関しては殆ど問題がなくなりました。
オーバークロック製品のサファイア製Nitro+のVega64がFrontierEditionより遅いのが気になりますが、メモリの使い方等に差異があるのかもしれません。何れにしても、大凡予測した理論値限界の速度が取れているので、非常に面白いベンチマークの結果になりました。
後日、新しいROCmのバージョンでPlaidMLのBenchmarkも取ってみたいと思います。
References
- HIP-TensorFlow https://github.com/ROCmSoftwarePlatform/hiptensorflow
- ROCm https://github.com/RadeonOpenCompute/ROCm
- MIOpen https://gpuopen.com/compute-product/miopen/
- ROCm-TensorFlow https://github.com/ROCmSoftwarePlatform/tensorflow
- vertex.ai Official Top http://vertex.ai/
- vertex.ai PlaidML http://vertex.ai/blog/announcing-plaidml
- PlaidML Github https://github.com/plaidml/plaidml
- CIFAR10 on the TensorFlow https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10
エンジニア募集中
GPU EATERの開発を一緒に行うメンバーを募集しています。
特にディープラーニング研究者、バックエンドエンジニアを積極採用中です。
募集職種はこちら