POSTS
ベンチマーク MATRIX MULTIPLICATION | TitanV TensorCore (FP16=>FP32)
Introduction
前回からの続きです。 行列の掛け算についてVolta世代から入ったTensorCore(FP16=>FP32)を含むベンチマークについて記述していきます。
Matrix Multiplication with TensorCore
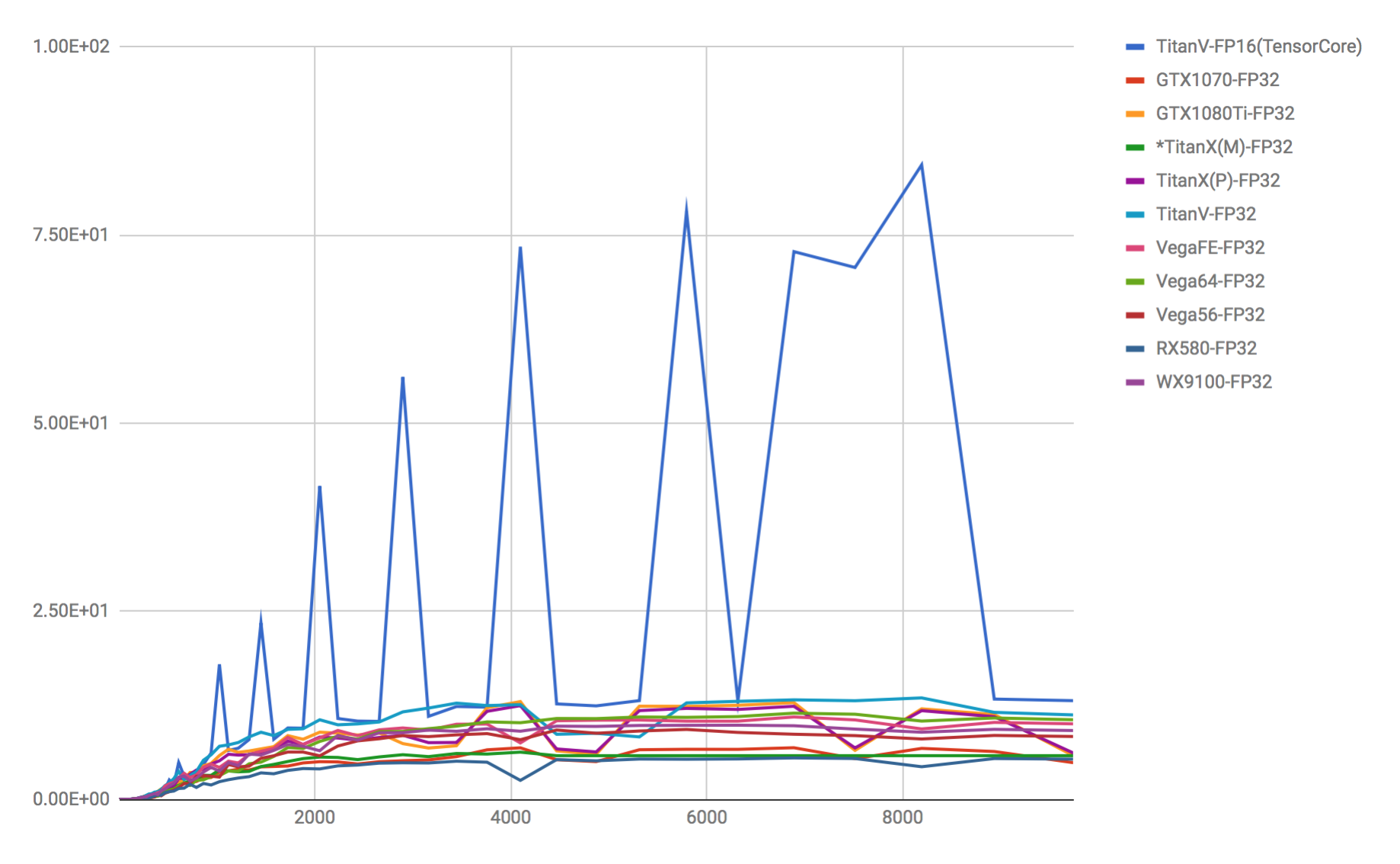 TitanVのTensorCore(FP16=>FP32)とその他はFP32のベンチマーク。
動作環境は前回同様、Ubuntu16.04にPython3.5+390.30,CUDA9.0,cuDNN7,TensorFlow1.6を入れています。
TitanVのTensorCore(FP16=>FP32)とその他はFP32のベンチマーク。
動作環境は前回同様、Ubuntu16.04にPython3.5+390.30,CUDA9.0,cuDNN7,TensorFlow1.6を入れています。
https://devblogs.nvidia.com/programming-tensor-cores-cuda-9/ *NVIDIAの公式に書いてあるような、本来FP16と比較するべき部分をFP32と比較、誇張した記述の仕方はあまりよくないのですが、このグラフもあえてFP32とTensorCore(FP16)を比較したグラフですので注意が必要です。
考察
グラフを見ると計算上の行列の要素数とGPUの計算用メモリのどこかがネックになりところどころスパイク状に尖っています。 この事から、TensorCoreを使用する場合は”速い要素数”と”遅い要素数”のルールがあると考えられます。
ちなみに、TensorCoreはMixed-Precisionと呼ばれる方式で、入力が16bit浮動小数点(FP16)、途中計算から32bit浮動小数点(FP32)にすることで精度を崩さないように工夫した特殊コアになります。DeepLearning計算を全てFP16にしてしまうと精度が足らず数値破綻を起こします。これを精度破綻が起こる部分にFP32を適応したことでFP16での効率的な演算速度を維持しながら、精度破綻を防いで効率よく計算を行う事が可能なるということのようです。
ですので、“FP32”ではなく”FP16”の指標だ、という部分を勘違いしないように注意が必要です。 もしくは、純粋なFP16でもありませんので、FP16=>FP32という風に特殊な記法で記述するべきかもしれません。
NVIDIAの資料によると、FP16のみではなく数値破綻部分をFP32で補填するので全ての層に対してTensorCore(FP16=>FP32)を使用しても大凡は学習においても問題がないとのこと。ただし、精度が必要な計算や特定のモデル、更新時の計算については、TensorCoreではなく通常のFP32を使わなければならないケースもあるということで、モデル内部での数値破綻が発生するかわからない場合はFP32を使用するといった運用になります。もし、クラウド上でFP32の精度の学習を行う場合は、10倍ほどの値段の費用対効果が悪いTeslaを継続して使用するか、世代をPascalに落として使うか、Vega56/64/FrontierEditionを使用するのが費用対効果が良い方法となります。
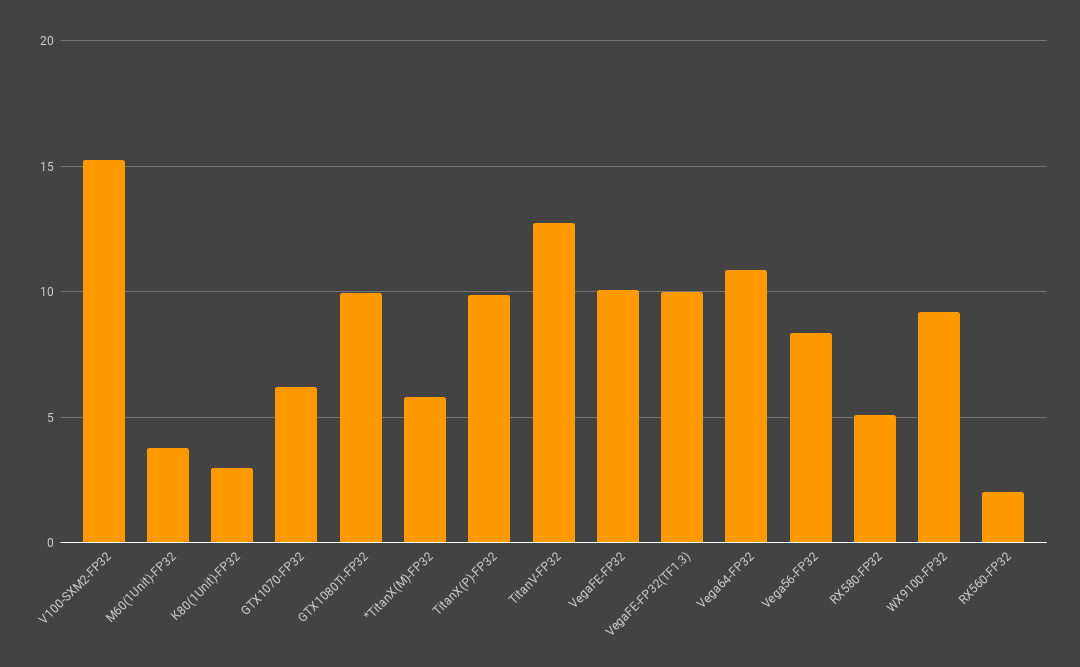 (*こちらはFP32のみ指標になります。)
(*こちらはFP32のみ指標になります。)
今回のベンチマークも行列の掛け算においてもほぼ、予測したとおりの結果となっており、公式で言われてるFlops指標と大凡一致し、違和感の無い指標が取れています。しかし、DeepLearningに於いてはFlops指標はあまり参考にならず、単純なFlops指標のように5倍以上等の差をつけるのは難しく、NVIDIAが自らP100とV100(TensorCore)で計測したResNet-50のベンチも資料を見る限り、3.7倍しか差が開かないという結果が出ていますので過剰な期待は注意が必要です。
今回、赤い文字を多く使っているのは、公式の”120TFlopsという数値はFP16の指標”だとは知らず、実際使ってみた時にFP32で全く速度が出ないことから、ドライバが古いか実装がされていないのだろうとしばらく勘違いをしていたからです。また、一般のブログ記事、スライドシェアやメディアによってはFP32の部分を120TFlopsと誤記されていたことから勘違いから勘違いを引き起こしてしまい混乱していたので、今回は赤文字を多く使用しました。
アナウンスされている公式値
| Tesla V100 PCle | Tesla V100 SXM2 | TitanV | |
|---|---|---|---|
| FP64 | 7 TFLOPS | 7.8 TFLOPS | ? TFLOPS |
| FP32 | 14 TFLOPS | 15.7 TFLOPS | ? TFLOPS |
| FP16=>FP32 | 112 TFLOPS | 125 TFLOPS | 110 TFLOPS |
前世代同様、TeslaとGeForce/Titan製品の速度が殆んど変わらないのは、Volta世代も同じくV100シリーズとTitanVの実質の速度もあまり変わりません。また、TitanVでのGamingの体感速度は期待するほど早くならず、1080Tiのオーバークロック版のデフォルトとほぼ変わりませんでした。GamingにおいてはTensorCoreは使われず、使ったとしても大量の線形代数演算より、シェーダーパイプライン上のオーバーヘッドやドローコール回数、テクスチャフェッチの方がボトルネックになりやすいからだと考えられます。
エンジニア募集中
GPU EATERの開発を一緒に行うメンバーを募集しています。
特にディープラーニング研究者、バックエンドエンジニアを積極採用中です。
募集職種はこちら
世界初のAMD GPU搭載の Deep Learning クラウド
GPU EATER https://gpueater.com
References
- TensorCore https://devblogs.nvidia.com/programming-tensor-cores-cuda-9/
- NVIDIA Japan Naruse’s slide https://www.slideshare.net/NVIDIAJapan/volta-tesla-v100
- Mixed-Precision training http://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html
- Volta specification http://www.nvidia.com/content/PDF/Volta-Datasheet.pdf