POSTS
MATRIX MULTIPLICATION ベンチマーク | AMD Vega and NVIDIA GeForce シリーズ比較
Introduction
株式会社ACUBE様より、Radeon Pro WX9100をお貸しして頂きましたので、そのレポートと共に弊社ブログへの結果を記載することに致しました。ご協力頂いた、ACUBE様に心より御礼を申し上げます。
このレポートは、Radeon Pro WX9100 製品を主軸に、同社 RadeonRX560/580, RadeonVega56/64/Frontier Edition, 他 NVIDIA 製品で、GeForceシリーズを比較したものになります。
元々の目的は、GPU クラウドコンピューティングにおける DeepLearning において、推論及び学習スピード、ライブラリの動作評価、費用対効果、耐久性及び熱処理効率、安定性、消費電力量、等などを比較し、導入を検討することですが、もっと多くの方々にGPUの能力について知って貰いたいがため記事に書くことにしました。
Matrix Multiplication
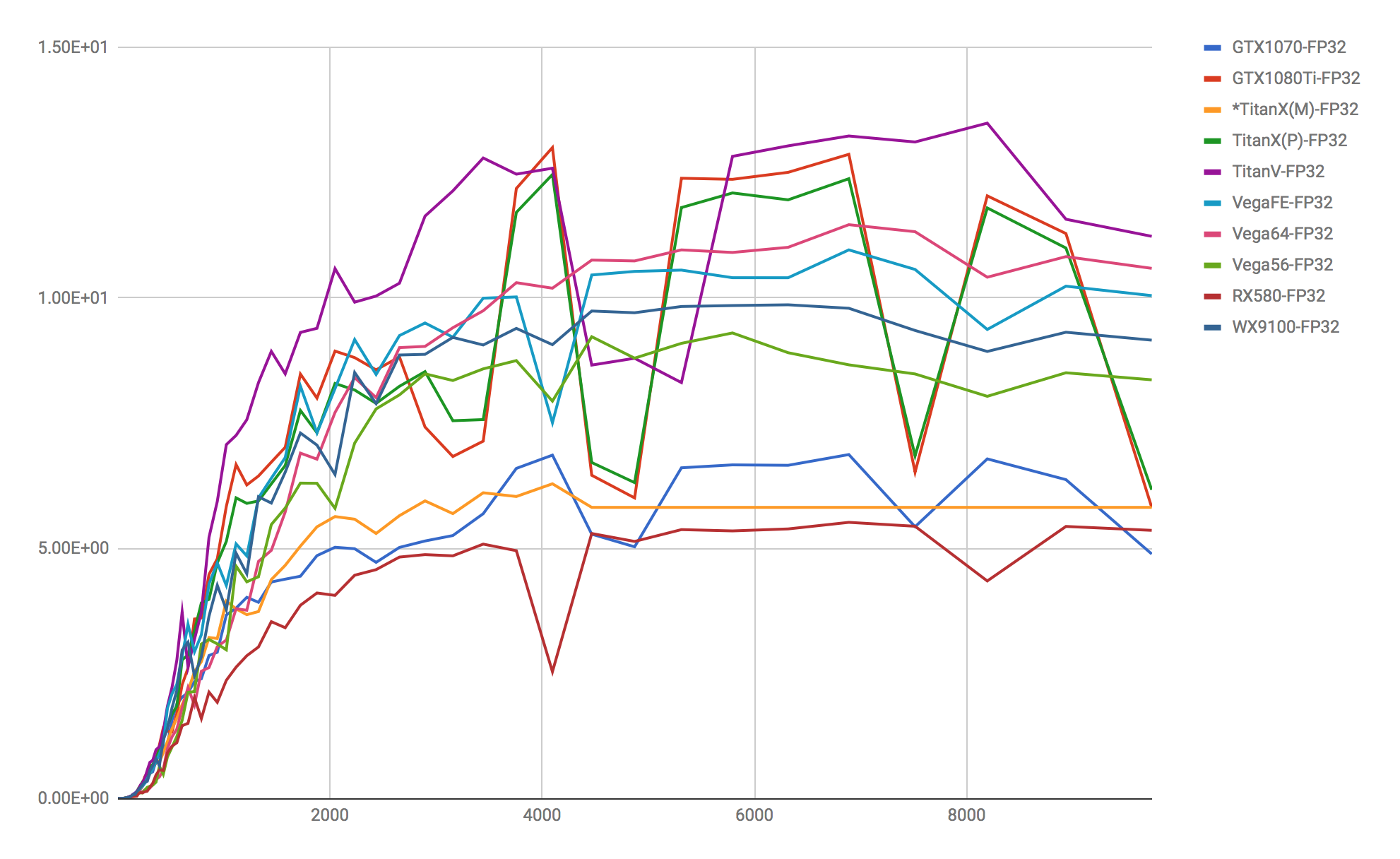 *TitanX(M)のみ途中で計測が途切れたので最後の値を機械的に入れています。
*TitanX(M)のみ途中で計測が途切れたので最後の値を機械的に入れています。
計算指標
計算指標としては、一般ニューラルネットワークにおける基礎、ρ(φiωji + βj)の計算で重要な行列 x 行列の速度、及び世界コンペティションやベンチマークでよく使用される CIFAR10 を TensorFlow の公式を使用し 、学習スピードを計測するものとしました。 今回の記事は、”行列計算”のみ掲載します。
行列の掛け算については、 https://github.com/yaroslavvb/stuff/blob/master/matmul_benchmark_seq.py を参照。
動作環境
AMD側 Ubuntu 16.04.3 x64 HIP-TensorFlow 1.0.1 Python 2.7 Driver: ROCm 1.7, AMDGPUPRO 17.50
NVIDIA側 Ubuntu 16.04.3 x64 TensorFlow r1.6 Python 3.5 Driver: 390.30, CUDA9.0, cuDNN7
HIP-TensorFlow1.0.1 については Python3.5 でのセットアップ方法が不明なため、 Python2.7 を使用しました。また、今ベンチマークにおける指標については CPU 能力は基本不要で、Python2.7⁄3.5 は変わらないと判断したため、NVIDIA 側は Python3.5+TensorFlow 最新(r1.6)を利用。また、TitanV のCIFAR10においては”TensorCore FP16”を利用できるようにしているため、完全に同じ条件とは言い難いことに注意。
ドライバは Radeon 側は ROCm ベースの最新(17.50)、 NVIDIA 側は 390.30 の完全 TitanV 対応しているドライバ及び、CUDA9.0+cuDNN7 を使用。NVIDIA側に肩を持つような構成になっていますが、HIP-TensorFlowのサポートスピードが早くないため、これは仕方がありません。
考察
行列の掛け算においてはほぼ、予測したとおりの結果となっており、公式で言われてるFlops指標と一致し、違和感の無い指標が取れています。TitanVについては32bit浮動小数点での計算においては、TensorCore(FP16)が使われず、公式の110TFlopsには全く届かないため、FP32を指標とするならば、1080Tiより少し早い程度になります。また、AMD製品もNVIDIA製品に負けず劣らず健闘しているところも注目すべき点でしょう。この事からライブラリをしっかりと組めればFP32指標では、NVIDIAとAMD双方において大きい差分は無いことを意味しますが、実際に後日記述するCIFAR10での差が明確に開くため、HIP-TensorFlowを改善するか、Vertex.aiのPlaidMLを使用すると言ったチューンナップが必用だということが分かっています。
- References
- HIP-TensorFlow https://github.com/ROCmSoftwarePlatform/hiptensorflow
- Vertex.ai PlaidML http://vertex.ai/blog/announcing-plaidml
- ROCm https://github.com/RadeonOpenCompute/ROCm
- MIOpen https://gpuopen.com/compute-product/miopen/
## エンジニア募集中
GPU EATERの開発を一緒に行うメンバーを募集しています。
特にディープラーニング研究者、バックエンドエンジニアを積極採用中です。
募集職種はこちら