POSTS
Comparing benchmarks between ROCm and NVIDIA(Inference)
Introduction
As the ROCm libraries has been updated, thoroughput of both inference and training has been improved.
In this post we would like to show some comparison between the AMD GPGPU environment on ROCm2.6 and NVIDIA RTX2080ti on Cuda 10 for Machine learning inference tasks.
Hardwares and softwares
Here are the Hardwares and softwares we have tested these benchmarks.
Hardwares and softwares of ROCm environment is as follows:
OS:Ubuntu16.04
GPU:AMD RadeonVII or AMD RX Vega 64
ROCm:2.4 or 2.6 or 2.7
And here is the those of NVIDIA Cuda:
OS:Ubuntu16.04
GPU:NVIDIA Geforce RTX2080ti
Cuda:
Software:Tensorflow 1.14
Result for benchmarks
ResNet50
This is a benchmark comparison for ResNet50 between Radeon VII on ROCm and GeForce RTX2080ti on Cuda.
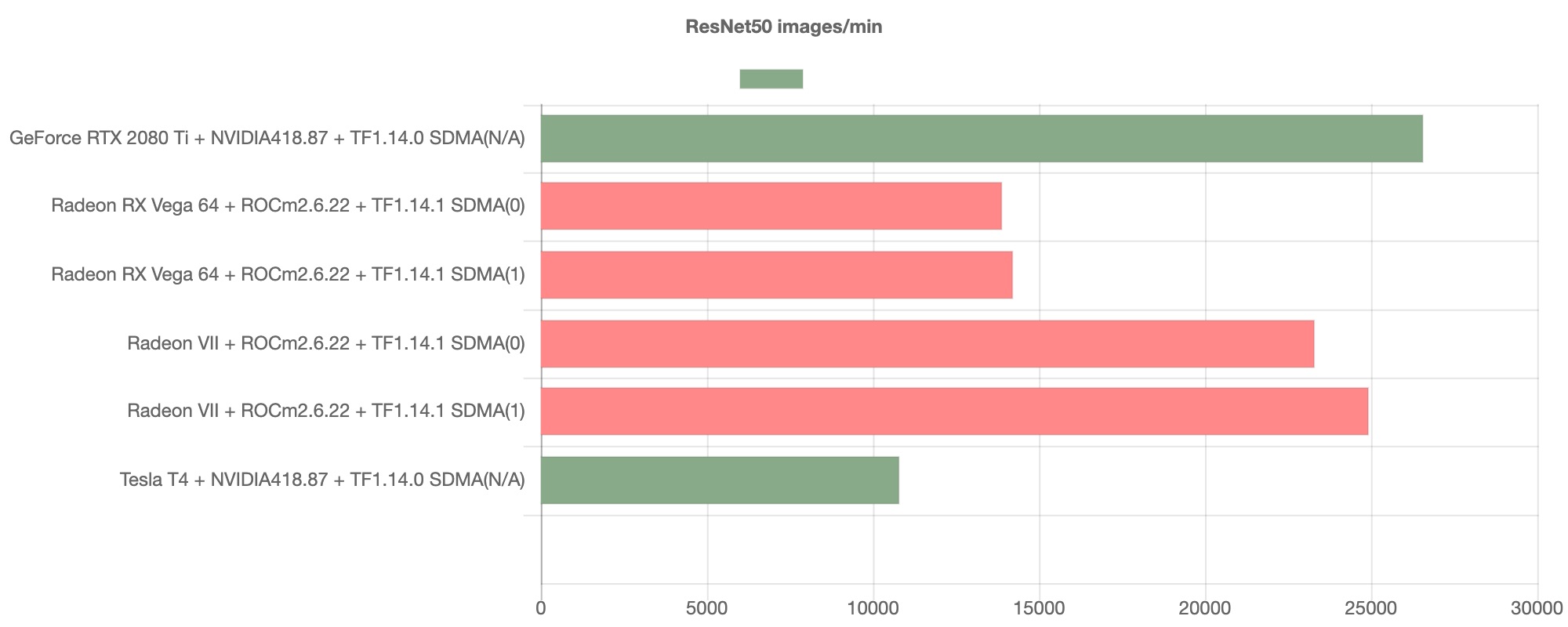 This results suggest Radeon VII on ROCm shows an improvement and it may go on par with NVIDIA RTX in the view of throughput.
This results suggest Radeon VII on ROCm shows an improvement and it may go on par with NVIDIA RTX in the view of throughput.
MobileNet
Next, we will show you the results for MobileNet.
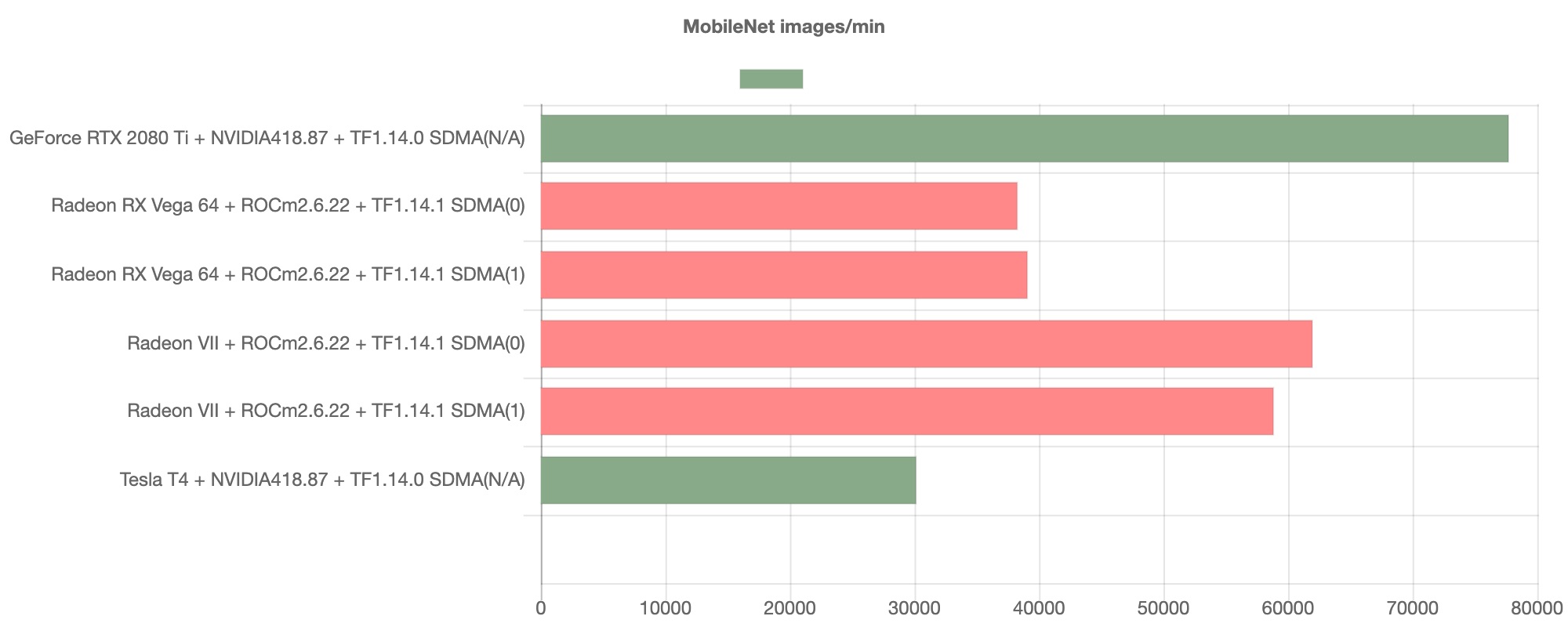 This benchmarks also show MobileNet model with Radeon VII on ROCm is also comperable with the model with NVIDIA RTX on Cuda.
h
This benchmarks also show MobileNet model with Radeon VII on ROCm is also comperable with the model with NVIDIA RTX on Cuda.
h
YOLOv3
We have shown the results that the models on ROCm on par with the model on Cuda. But how about the YOLOv3?
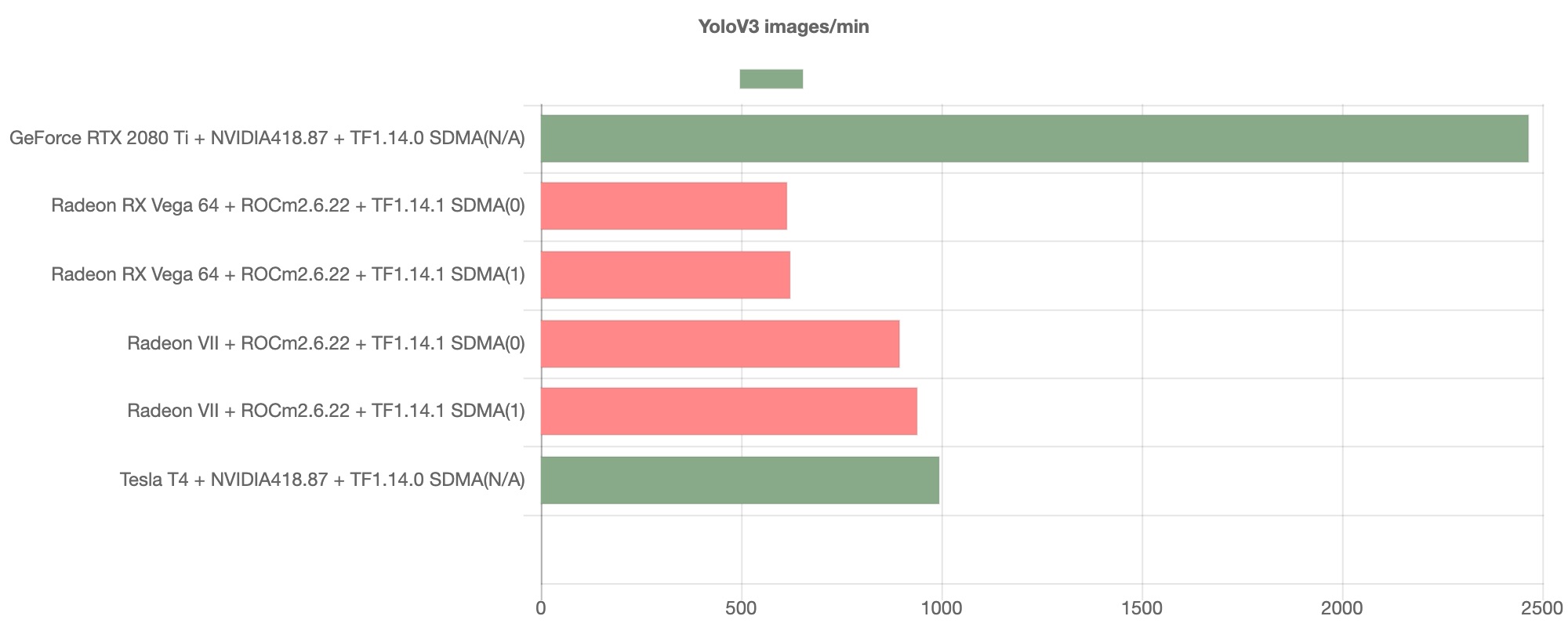 This image shows YOLOv3 with Radeon VII goes much worse than the model with RTX 2080ti.
This image shows YOLOv3 with Radeon VII goes much worse than the model with RTX 2080ti.
Inception-V3
And here are the results of the Inception-V3.
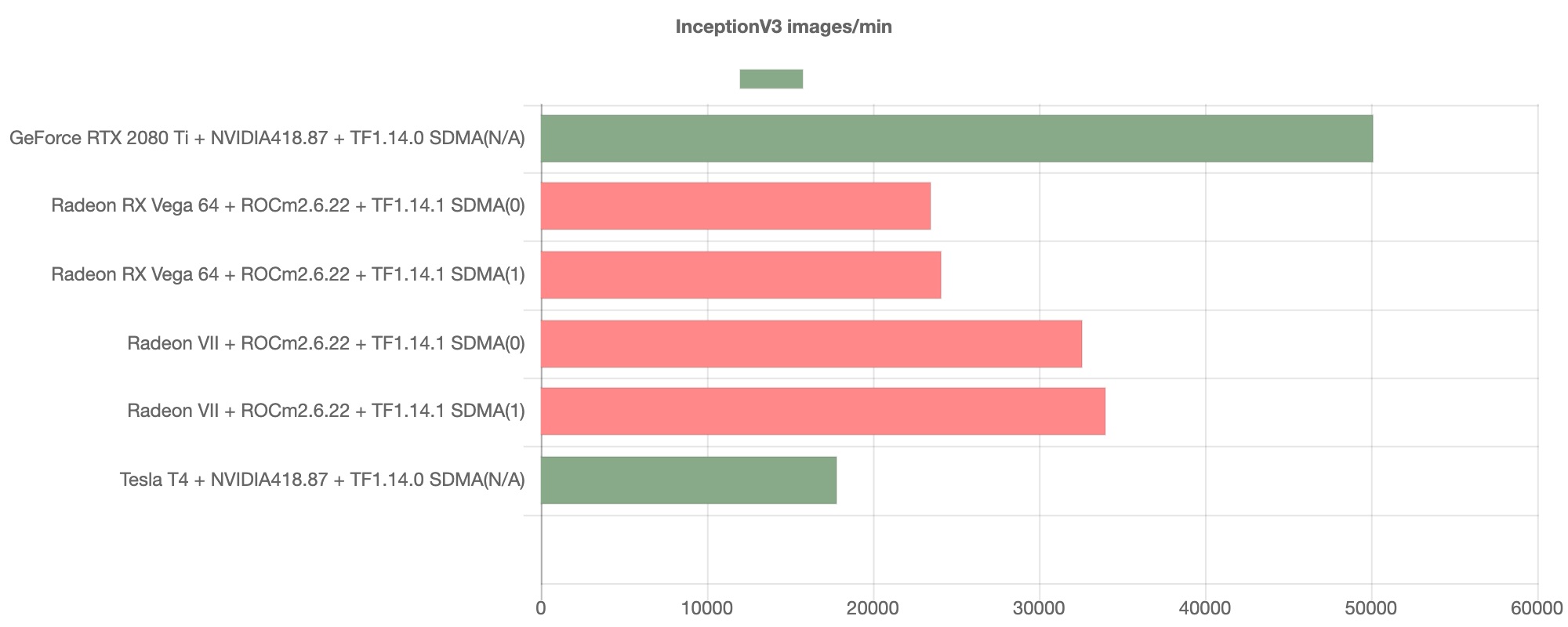 Not as noticeable as YOLOv3, you can see that the throughput of AMD GPUs is struggling compared to that of NVIDIA GPUs.
Not as noticeable as YOLOv3, you can see that the throughput of AMD GPUs is struggling compared to that of NVIDIA GPUs.
Summary
As mentioned above, we have compared the benchmark of Machine learning inference tasks under the current ROCm environment and those with NVIDIA GPU, and currently the models like ResNet and MobileNet ensure good throughput with AMD GPU. On the other hand, it seems that the models such as YOLOv3 and Inception-V3 would be inferior to those with NVIDIA GPU in terms of throughput. In terms of the inference tasks, there seems to be room for using AMD GPU selection depending on the machine leaning tasks. And we will like to be seeking for further investigation for what causes the bottlenecks of the models with ROCm.
References
- TensorFlor-ROCm / HipCaffe / PyTorch-ROCm / Caffe2 installation https://rocm-documentation.readthedocs.io/en/latest/Deep_learning/Deep-learning.html
- ROCm https://github.com/ROCmSoftwarePlatform
- MIOpen https://gpuopen.com/compute-product/miopen/
- GPUEater tensorflow-rocm installer https://github.com/aieater/rocm_tensorflow_info
Are you interested in working with us?
We are actively looking for new members for developing and improving GPUEater cloud platform. For more information, please check here.