POSTS
Benchmark CIFAR10 on TensorFlow with ROCm on AMD GPUs vs CUDA9 and cuDNN7 on NVIDIA GPUs
Introduction
I’m going to continue my description of the CIFAR10 benchmark, from where I left off.
Related articles
Mar 7, 2018 Benchmarks on MATRIX MULTIPLICATION | A comparison between AMD Vega and NVIDIA GeForce series Mar 20, 2018 Benchmarks on MATRIX MULTIPLICATION | TitanV TensorCore (FP16=>FP32)
CIFAR10
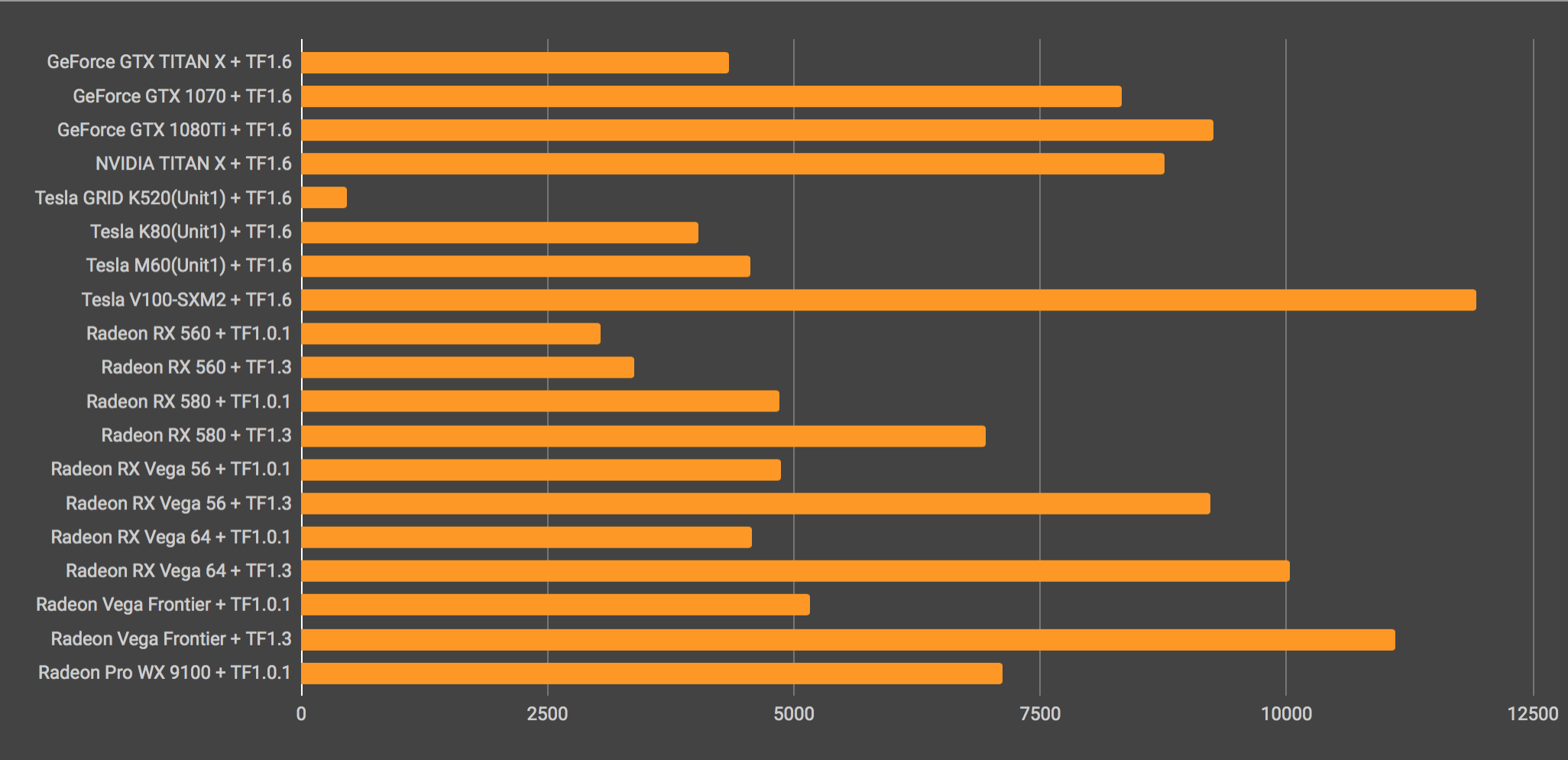 Average examples pre second
Average examples pre second
Introduction
I took the CIFAR10 dataset, which is widely used throughout the world in competitions and benchmarks, and used the public release of TensorFlow in order to measure its training speed.
In this article I’ll only be writing about CIFAR10.
I used the following source code when performing the benchmarks. https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10
System requirements
AMD(TF1.0.1): Ubuntu 16.04.3 x64 HIP-TensorFlow 1.0.1 Python 2.7 Driver: ROCm 1.7
AMD(TF1.3): Ubuntu 16.04.4 x64 TensorFlow 1.3 Python 3.5 Driver: ROCm 1.7.137
NVIDIA(TF1.6): Ubuntu 16.04.4 x64 TensorFlow r1.6 Python 3.5 Driver: 390.30, CUDA9.0, cuDNN7
Discussion
The results were close to those of the previous benchmark on matrix operations. I got strange results when using HIP–TensorFlow 1.0.1, with the first–generation RX580 winning out over the Vega64, so it was apparent that there was some sort of issue surrounding the AMD chip, but using the new ROCm and a higher version of Tensorflow 1.3, the speed issues nearly completely vanished.
I found it interesting that the overclocked Sapphire Nitro+ Vega64 was slower than the Frontier Edition, but perhaps there are some differences in the way that they manage memory and the like. Regardless, the fact that I was able to record speeds at approximately the theoretical limit made the results of this benchmark quite fascinating.
I hope to perform tests on PlaidML with a new version of ROCm for another article in the near future.
References
- HIP-TensorFlow https://github.com/ROCmSoftwarePlatform/hiptensorflow
- ROCm https://github.com/RadeonOpenCompute/ROCm
- MIOpen https://gpuopen.com/compute-product/miopen/
- ROCm-TensorFlow https://github.com/ROCmSoftwarePlatform/tensorflow
- vertex.ai Official Top http://vertex.ai/
- vertex.ai PlaidML http://vertex.ai/blog/announcing-plaidml
- PlaidML Github https://github.com/plaidml/plaidml
- CIFAR10 on the TensorFlow https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10
Are you interested in working with us?
We are actively looking for new members for developing and improving GPUEater cloud platform. For more information, please check here.