POSTS
Benchmarks on MATRIX MULTIPLICATION | TitanV TensorCore (FP16=>FP32)
Introduction
This is continued from the last article. I’ll be writing about benchmarks for the multiplications of matrices, including for the TensorCore (FP16=>FP32), which was first incorporated in the Volta.
Matrix Multiplication with TensorCore
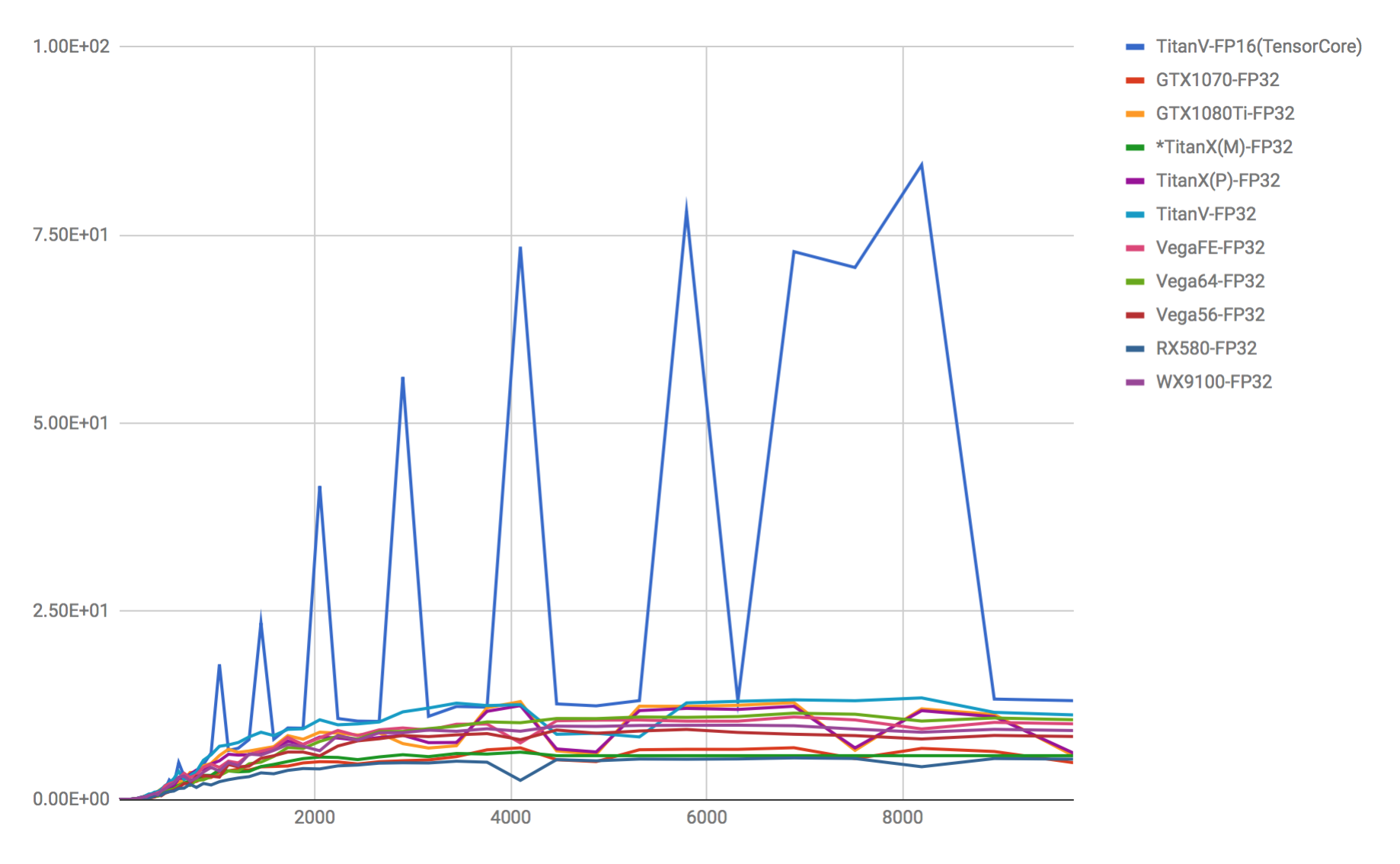 NVIDIA TitanV’s TensorCore (FP16=>FP32) and other FP32 benchmarks.
I used the same setup as before: Ubuntu16.04 incorporating Python3.5+390.30, CUDA9.0, cuDNN7, and TensorFlow1.6.
NVIDIA TitanV’s TensorCore (FP16=>FP32) and other FP32 benchmarks.
I used the same setup as before: Ubuntu16.04 incorporating Python3.5+390.30, CUDA9.0, cuDNN7, and TensorFlow1.6.
https://devblogs.nvidia.com/programming-tensor-cores-cuda-9/ *It’s not really ideal to make comparisons against FP32 where they should be made against FP16, and give exaggerated descriptions the way they do on NVIDIA’s official site, but please note that this graph does make comparisons between FP32 and TensorCore (FP16).
Considerations
If you look at the graph, you’ll see that there is a bottleneck somewhere in the calculated number of elements in the matrices and the GPU calculation memory, creating spikes in places. Therefore, it would appear that when using Tensor Core, there are rules for “fast numbers of elements” and “slow numbers of elements.”
Incidentally, TensorCore uses a method called Mixed-Precision, a special core that is engineered to maintain precision by taking 16-bit floating point inputs (FP16) and accumulating the result into 32-bit floating point (FP32). If Deep Learning calculations were carried out using only FP16, the lack of precision would result in numerical failures. It appears that applying FP32 to the part where precision failures would occur makes it possible to maintain the efficient computing speeds of FP16, and carry out calculations efficiently while preventing precision failure.
Therefore, we need to remember that these are figures for “FP16” rather than”FP32” to avoid confusion . Or, given that this is not purely FP16, perhaps this should be described in a particular way such as FP16=>FP32.
According to materials provided by NVIDIA, there are no real issues with learning even if TensorCore(FP16=>FP32) is used for all layers, as it uses not only FP16 but augments any numerical failures with FP32. However, there may be cases where it is necessary to use regular FP32 rather than TensorCore, such as for calculations or particular models that require precision, and calculations for updates. Therefore, for operational purposes, FP32 should be used if one is not sure if a numerical failure may occur within the model. When conducting learning at FP32 precision in the cloud, you have the choice of continuing to use Tesla, which is not cost effective as it costs 10 times as much, or downgrading to Pascal or using Vega56/64/FrontierEdition as more cost effective methods.
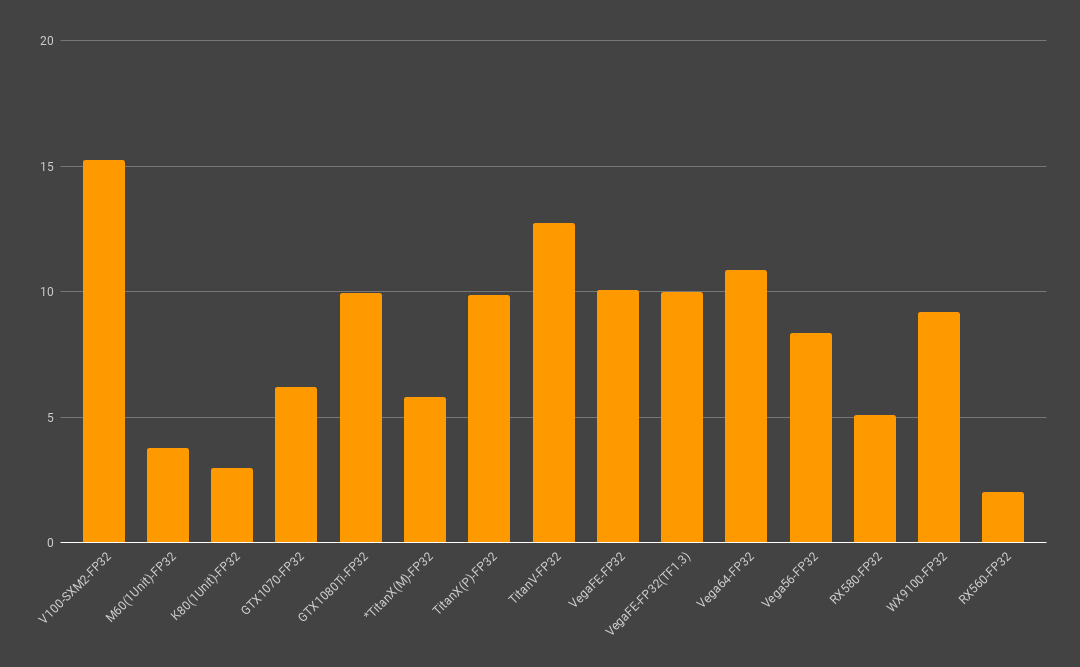 (*These are figures for FP32 only)
(*These are figures for FP32 only)
The benchmarks for the multiplication of matrices were almost exactly as predicted, more or less matching the official Flops benchmarks, so I was able to achieve figures that made sense. However, Flops benchmarks are not really relevant for DeepLearning, and it is difficult to achieve differences of over five times in the same way as for simple Flops benchmarks. NVIDIA itself measured benchmarks for ResNet-50 using P100 and V100 (TensorCore), and from what I can see of the materials, they only achieved a difference of 3.7 times, so expectations need to be kept in check.
The reason I am using so much red text this time is because I didn’t realize that the official figure of “120TFlops” was a benchmark for FP16, and as I couldn’t achieve any real speeds with FP32 when I actually used it, for a while I mistakenly thought that the driver was either old or had not been implemented. In addition, some blog articles by the general public, as well as slide shares and media, had misunderstood and erroneously put down 120TFlops for FP32, causing even more confusion, so I have used a lot of red text.
The official figures as published
| Tesla V100 PCle | Tesla V100 SXM2 | TitanV | |
|---|---|---|---|
| FP64 | 7 TFLOPS | 7.8 TFLOPS | ? TFLOPS |
| FP32 | 14 TFLOPS | 15.7 TFLOPS | ? TFLOPS |
| FP16=>FP32 | 112 TFLOPS | 125 TFLOPS | 110 TFLOPS |
The reason that there is almost no difference in speed between the Tesla and GeForce/Titan products, as with the previous generation, is because there is almost no difference in actual speeds for the V100 series and the TitanV for the Volta generation. In addition, the sensory speeds for gaming experiences using TitanV were not as fast as expected, and were almost the same as the default settings for the overclocked version of the 1080Ti. This would appear to be because TensorCore is not used in gaming, and even if it were used, the massive numbers of linear algebraic computations would tend to create bottlenecks in the overheads of shader pipelines, number of draw calls, or texture fetch.
Are you interested in working with us?
We are actively looking for new members for developing and improving GPUEater cloud platform. For more information, please check here.
The world’s first AMD GPU-based Deep Learning Cloud.
GPU EATER https://gpueater.com
References
- TensorCore https://devblogs.nvidia.com/programming-tensor-cores-cuda-9/
- NVIDIA Japan Naruse’s slide https://www.slideshare.net/NVIDIAJapan/volta-tesla-v100
- Mixed-Precision training http://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html
- Volta specification http://www.nvidia.com/content/PDF/Volta-Datasheet.pdf