POSTS
Benchmarks on MATRIX MULTIPLICATION | A comparison between AMD Vega and NVIDIA GeForce series
Introduction
ACUBE Corp. graciously allowed us to borrow a Radeon Pro WX9100, so we have decided to make a report on the card and a record of the results here on our company blog. We would like to extend our heartfelt gratitude to ACUBE Corp. for this opportunity.
This report focuses on the Radeon Pro WX9100 card and makes comparisons with the Radeon RX560/580 and RadeonVega56/64/Frontier Edition from the same manufacturer, as well as with the GeForce series from NVIDIA.
Our original goal was simply to compare a number of variables as they pertain to Deep Learning in GPU cloud computing, including the card’s power consumption, stability, durability and heat treatment performance, cost-effectiveness, library operation assessment, as well as inference and learning speeds, and consider implementing this card for our own use. However, we felt that it would be a good idea to show the capabilities of this GPU to a wider audience and thus decided to write this article.
MATRIX MULTIPLICATION
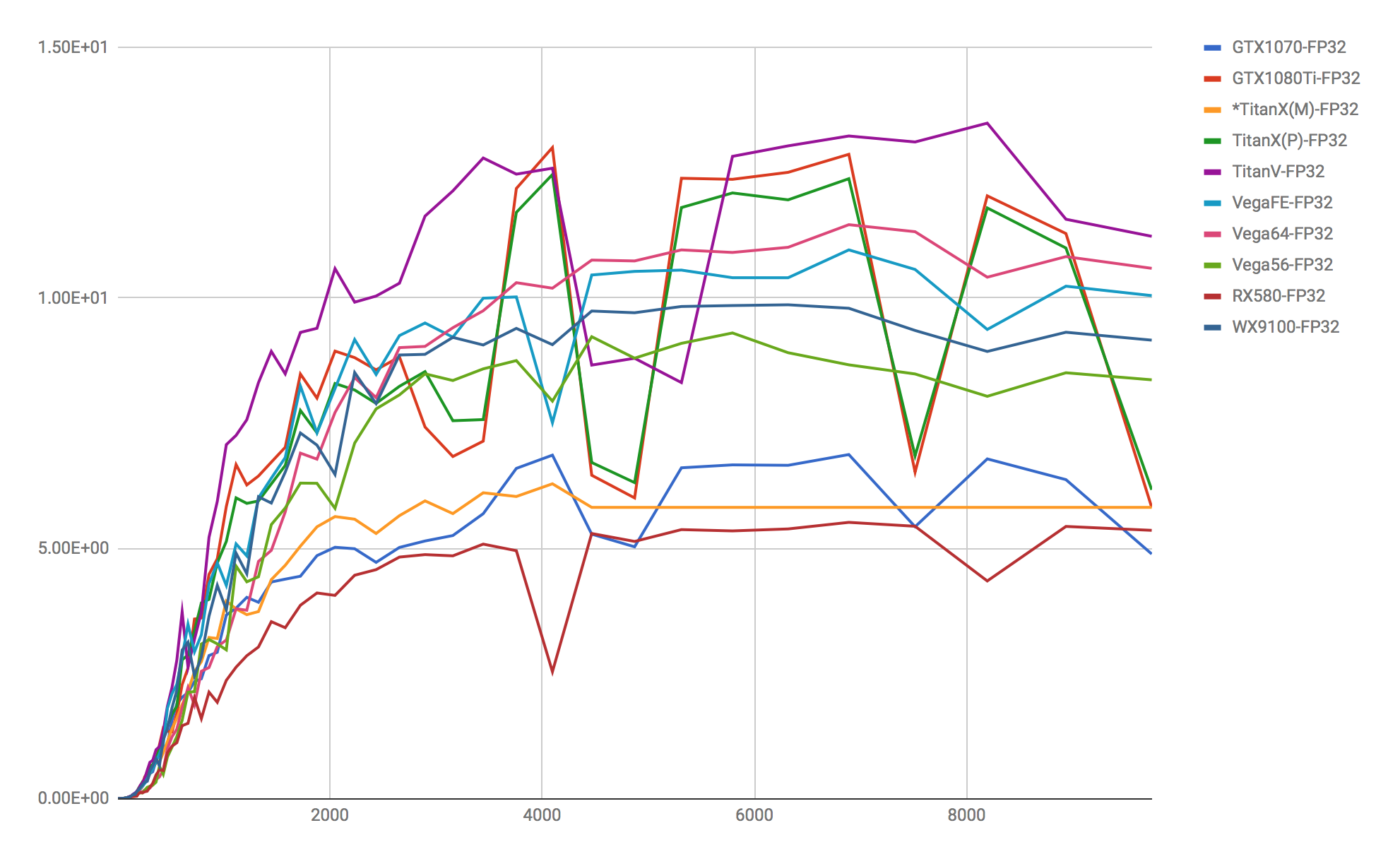
*Calculations for the TitanX(M) only were interrupted mid-way, so we have inserted the final values mechanically.
Calculated Metrics
The calculated metrics we used to measure learning speeds were the foundation for general neural networks—the important factor of matrix multiplication speed via the ρ(φiωji + βj) calculation, as well as CIFAR10, often used in global competitions and benchmarks, using TensorFlow formulas. We will post only the matrix multiplications for this article.
Refer to this link for more information on matrix multiplication: https://github.com/yaroslavvb/stuff/blob/master/matmul_benchmark_seq.py
Operating Environments
For AMD: Ubuntu 16.04.3 x64 HIP-TensorFlow 1.0.1 Python 2.7 Driver: ROCm 1.7, AMDGPUPRO 17.50
For NVIDIA: Ubuntu 16.04.3 x64 TensorFlow r1.6 Python 3.5 Driver: 390.30, CUDA9.0, cuDNN7
The method for setting up HIP-TensorFlow1.0.1 on Python 3.5 was unclear, so we used Python 2.7. Furthermore, as we judged there to be no difference between Python 2.7 and 3.5 due to the fact that CPU capability is basically unnecessary as a metric for benchmarks, we used Python 3.5 and TensorFlow’s newest version (r1.6) for the NVIDIA cards. Also, because we have made it possible to use TensorCore FP16 with CIFAR10 for the Titan V, please be aware that it is difficult to say that everything was run under exactly the same conditions.
We used the newest version of the ROCm driver (17.50) for the Radeon cards and the 390.30 driver providing full support for Titan V as well as CUDA9.0 + cuDNN7 for the NVIDIA cards. This configuration seems to give an advantage to the NVIDIA cards, but, as support speed for HIP-TensorFlow is not very fast, there is nothing we could do concerning this point.
Discussion
As far as matrix multiplication goes, the results we found were almost exactly as we had predicted. They match with the FLOPS metric laid out in the formulas, and we were able to produce metrics that didn’t seem strange at all. TensorCore (FP16) is not used for calculating 32-bit floating point representation for the Titan V, and it couldn’t reach 110TFLOPS at all, making it slightly faster than the 1080Ti if we use FPS32 as the metric here. We also feel that it should be pointed out that the AMD cards are fighting on even ground with NVIDIA’s cards. This means that, based on the FP32 metric with solidly assembled libraries, there is hardly any difference between NVIDIA and AMD. However, as the difference between the two becomes apparent in the CIFAR10 results which we will post in a future article, we can see that a slight tune-up will be necessary, such as making improvements to HIP-TensorFlow or using Vertex.AI’s PlaidML.
References
- HIP-TensorFlow https://github.com/ROCmSoftwarePlatform/hiptensorflow
- Vertex.AI PlaidML http://vertex.ai/blog/announcing-plaidml
- ROCm https://github.com/RadeonOpenCompute/ROCm
- MIOpen https://gpuopen.com/compute-product/miopen/
## Are you interested in working with us? We are actively looking for new members for developing and improving GPUEater cloud platform. For more information, please check here.